

아주 간단한 문제를 하나 내볼까 합니다. “나는 배가 고파서 밥을 _______.” 다음 문장의 빈칸에 들어갈 적절한 단어는 무엇일까요? ‘배가 고프다’는 동기에 의해서 ‘밥’이라는 대상에 적용할 수 있는 적절한 행위가 무엇인지에 대해 생각해보면 ‘먹는다’는 단어가 빈칸에 들어갈 적절한 단어임을 알 수 있습니다.
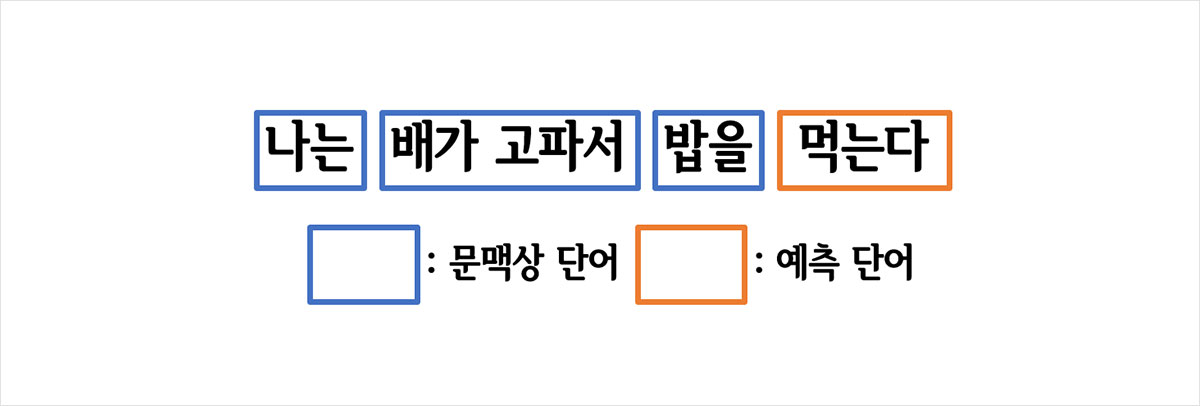
그림 1.
이 과정이 매끄럽게 느껴진다면 그것은 당연한 것입니다. 왜냐하면 우리는 인간이기 때문입니다. 하지만 당연함을 잠시 배제한다면 이런 의문이 들 수 있습니다. ‘밥’이라는 대상에 대응하는 적절한 행위가 왜 먹는 것인가? 이 질문에 대한 답은 무엇일까요?
이처럼 당연하게 받아들여지는 맥락을 아는 것은 인간의 타고난 논리적 사고에 따른 것일 수도 있고, 수없이 많은 언어 사용의 경험을 통한 습득일 수도 있습니다. 그 방법이 무엇이든 언어를 이해하기 위해서는, 단순히 문장의 구조를 이해하는 것을 넘어서 내용과 문맥에 대한 이해가 필요합니다. 그렇기에 언어의 사용은 인간만이 가진 특권이라고 여겨지기도 합니다.
하지만 오늘날 우리는 새로운 개체에게 우리 인간의 언어를 이해시킬 필요성이 생겼는데요. 바로 인공지능입니다. 사람들이 표현하는 언어의 의미를 이해하고, 정보를 추출하며, 나아가 직접 언어를 생성해낼 수 있는 언어이해 기술이 인공지능 연구의 한 분야로 발전하고 있고, 이러한 인공지능의 언어이해 기술을 종합하여 자연어 처리(Natural Language Processing: NLP)라 합니다. 이번 기사를 통해 이 자연어 처리 기술에 대해 알아보겠습니다.
자연어 처리를 위해서는 인간의 언어를 컴퓨터가 이해할 수 있도록 바꾸는 작업이 필요합니다. 컴퓨터는 숫자로 언어를 이해할 수 있기 때문에 인간이 사용하는 자연어를 0과 1의 이진법으로 표현할 수 있어야 합니다. 문자를 숫자로 변환하는 여러 기법 중 가장 기본적인 표현 방법은 원-핫 인코딩(One-Hot Encoding)입니다. 원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을, 다른 인덱스에는 0의 값을 부여하는 벡터 표현 방식입니다. 예문을 통해 원-핫 인코딩을 이해해보겠습니다.
“나는 공대상상 겨울호 기사를 읽는다.”라는 문장이 있을 때, 이 문장은 “나”, ”는”, ”공대상상”, “겨울호”, “기사”, “를”, “읽는다”라는 7개의 단어로 나뉠 수 있습니다. 이 문장에 원-핫 인코딩을 통해 부여한 벡터를 정리하면 아래의 표와 같습니다.
이처럼 당연하게 받아들여지는 맥락을 아는 것은 인간의 타고난 논리적 사고에 따른 것일 수도 있고, 수없이 많은 언어 사용의 경험을 통한 습득일 수도 있습니다. 그 방법이 무엇이든 언어를 이해하기 위해서는, 단순히 문장의 구조를 이해하는 것을 넘어서 내용과 문맥에 대한 이해가 필요합니다. 그렇기에 언어의 사용은 인간만이 가진 특권이라고 여겨지기도 합니다.
하지만 오늘날 우리는 새로운 개체에게 우리 인간의 언어를 이해시킬 필요성이 생겼는데요. 바로 인공지능입니다. 사람들이 표현하는 언어의 의미를 이해하고, 정보를 추출하며, 나아가 직접 언어를 생성해낼 수 있는 언어이해 기술이 인공지능 연구의 한 분야로 발전하고 있고, 이러한 인공지능의 언어이해 기술을 종합하여 자연어 처리(Natural Language Processing: NLP)라 합니다. 이번 기사를 통해 이 자연어 처리 기술에 대해 알아보겠습니다.
자연어 처리를 위해서는 인간의 언어를 컴퓨터가 이해할 수 있도록 바꾸는 작업이 필요합니다. 컴퓨터는 숫자로 언어를 이해할 수 있기 때문에 인간이 사용하는 자연어를 0과 1의 이진법으로 표현할 수 있어야 합니다. 문자를 숫자로 변환하는 여러 기법 중 가장 기본적인 표현 방법은 원-핫 인코딩(One-Hot Encoding)입니다. 원-핫 인코딩은 단어 집합의 크기를 벡터의 차원으로 하고, 표현하고 싶은 단어의 인덱스에 1의 값을, 다른 인덱스에는 0의 값을 부여하는 벡터 표현 방식입니다. 예문을 통해 원-핫 인코딩을 이해해보겠습니다.
“나는 공대상상 겨울호 기사를 읽는다.”라는 문장이 있을 때, 이 문장은 “나”, ”는”, ”공대상상”, “겨울호”, “기사”, “를”, “읽는다”라는 7개의 단어로 나뉠 수 있습니다. 이 문장에 원-핫 인코딩을 통해 부여한 벡터를 정리하면 아래의 표와 같습니다.
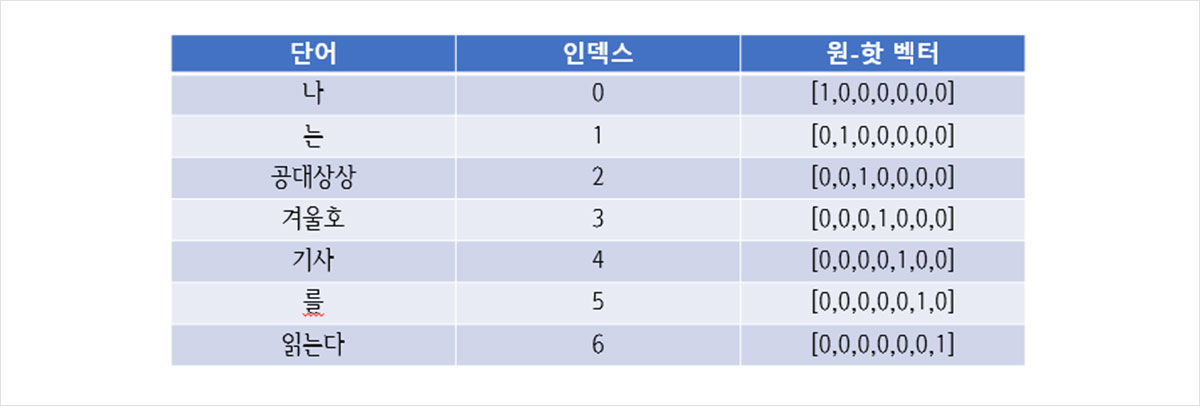
그림 2. 원-핫 인코딩 예문
만약 여러 예문이 주어진다면 중복되어 사용된 단어들을 제거한 단어들의 모임을 만들고 각 단어들에 인덱스를 부여하여 벡터로 표현하는 것이 원-핫 인코딩의 방법입니다. 원-핫 인코딩은 문자를 숫자로 변환하여 컴퓨터에 입력할 수 있는 가장 단순하면서도 쉬운 방법입니다. 그렇다면 원-핫 인코딩을 통해 컴퓨터가 단어를 입력받았을 때 컴퓨터가 언어를 이해했다고 생각할 수 있을까요? 아마 아닐 것입니다.
다시 처음의 질문으로 돌아가 “나는 배가 고파서 밥을 _______.” 라는 문장의 빈칸에 ‘먹는다’라는 단어가 들어가면 적절한 이유는 문맥상 그렇기 때문입니다. “밥”이라는 대상에 작용할 수 있는 가장 타당한 행위는 먹는 것이고 그렇기에 빈칸에 들어가야 할 단어는 “먹는다” 인 것입니다. 하지만 원-핫 인코딩은 단어들 간의 유사도를 전혀 반영하지 못하기에 이러한 문맥상 해석이 불가능합니다. 그렇기에 컴퓨터가 언어를 이해했다고 볼 수 없는 것이지요. 더불어 일상적인 언어에 쓰이는 단어는 몇천 개에 이르는데 원-핫 인코딩 방법으로 이들 단어 각각에 벡터를 부여한다면 입력 데이터의 차원이 지나치게 높아진다는 단점도 있습니다.
이러한 단점을 해결하기 위해서는 문자를 숫자로 표현할 때, 단어 간의 의미의 유사도를 파악할 수 있도록 단어의 의미를 벡터화하는 방법이 필요했습니다. 단어의 의미를 벡터화하는 것을 임베딩(Embedding)이라 하는데, 임베딩의 대표적인 방법의 하나가 워드투벡터(Word2Vec)입니다. 원-핫 인코딩은 각각의 단어들이 독립된 차원으로 표현된다면 워드투벡터는 우리가 정한 개수의 차원으로 단어를 대응시켜서 표현합니다. 예컨대 단어들의 속성을 2차원으로 표현할 것이라고 정하면 그 속성을 2차원 벡터에 대응시키는 것입니다. 이렇게 임베딩된 벡터는 더는 독립적이지 않고 하나의 정보가 여러 차원에 분산되어 표현되게 됩니다. 이를 통해 훨씬 적은 차원으로 단어를 표현할 수 있게 되고 나아가 벡터의 유사성을 통해 단어들 사이의 유사성을 판단할 수 있는 것입니다. 워드투벡터의 핵심 아이디어는 단어의 주변을 보면 그 단어를 안다는 것인데요, 예문을 통해 워드투벡터로 문자를 벡터화하는 방법을 이해해보겠습니다.
다시 처음의 질문으로 돌아가 “나는 배가 고파서 밥을 _______.” 라는 문장의 빈칸에 ‘먹는다’라는 단어가 들어가면 적절한 이유는 문맥상 그렇기 때문입니다. “밥”이라는 대상에 작용할 수 있는 가장 타당한 행위는 먹는 것이고 그렇기에 빈칸에 들어가야 할 단어는 “먹는다” 인 것입니다. 하지만 원-핫 인코딩은 단어들 간의 유사도를 전혀 반영하지 못하기에 이러한 문맥상 해석이 불가능합니다. 그렇기에 컴퓨터가 언어를 이해했다고 볼 수 없는 것이지요. 더불어 일상적인 언어에 쓰이는 단어는 몇천 개에 이르는데 원-핫 인코딩 방법으로 이들 단어 각각에 벡터를 부여한다면 입력 데이터의 차원이 지나치게 높아진다는 단점도 있습니다.
이러한 단점을 해결하기 위해서는 문자를 숫자로 표현할 때, 단어 간의 의미의 유사도를 파악할 수 있도록 단어의 의미를 벡터화하는 방법이 필요했습니다. 단어의 의미를 벡터화하는 것을 임베딩(Embedding)이라 하는데, 임베딩의 대표적인 방법의 하나가 워드투벡터(Word2Vec)입니다. 원-핫 인코딩은 각각의 단어들이 독립된 차원으로 표현된다면 워드투벡터는 우리가 정한 개수의 차원으로 단어를 대응시켜서 표현합니다. 예컨대 단어들의 속성을 2차원으로 표현할 것이라고 정하면 그 속성을 2차원 벡터에 대응시키는 것입니다. 이렇게 임베딩된 벡터는 더는 독립적이지 않고 하나의 정보가 여러 차원에 분산되어 표현되게 됩니다. 이를 통해 훨씬 적은 차원으로 단어를 표현할 수 있게 되고 나아가 벡터의 유사성을 통해 단어들 사이의 유사성을 판단할 수 있는 것입니다. 워드투벡터의 핵심 아이디어는 단어의 주변을 보면 그 단어를 안다는 것인데요, 예문을 통해 워드투벡터로 문자를 벡터화하는 방법을 이해해보겠습니다.

그림 3. 중심단어와 주변단어의 결정
“King is a brave man”, “Queen is a beautiful woman” 두 예문에서 큰 의미적 가치가 없는 두 단어 “is”와 “a”를 제하면 “King brave man”, “Queen beautiful woman”이 됩니다. 예측해야 하는 단어를 중심 단어라고 하고, 예측에 사용되는 단어를 주변 단어라고 하는데 이 주변 단어의 허용 범위를 윈도우라고 합니다. 예를 들어 [그림3]에서 중심 단어 앞뒤로 하나의 단어를 주변 단어로 보기 때문에 윈도우의 크기가 1이 되는 것입니다.
윈도우의 크기가 정해지면 워드투벡터는 주변 단어를 통해 중심 단어를 예측하는 학습을 하게 됩니다. 윈도우를 계속 움직여 주변 단어와 중심 단어의 선택을 바꿔가며 학습하면 점점 단어들의 관계를 이해하게 되는 것이지요. 이때 이 워드투벡터의 학습 방법에 대해 알아보겠습니다. 우선 워드투벡터는 얕은 인공신경망 모델인데요, 인공신경망이란 인간의 뉴런에서 착안하여 만든 학습 알고리즘으로 겹겹이 쌓인 층으로 구성되어 있습니다. 층은 크게 입력값이 들어가는 입력층, 출력값이 나오는 출력층, 그리고 그 사이에 입력값들이 변환되는 은닉층(hidden layer) 세 가지로 구분할 수 있는데요, 워드투벡터는 은닉층이 하나이기 때문에 얕은 인공신경망으로 분류됩니다. 이때 은닉층에 부여되는 벡터가 단어를 임베딩한 벡터가 되고 따라서 그것을 알아내는 것이 워드투벡터의 학습 과정입니다.
윈도우의 크기가 정해지면 워드투벡터는 주변 단어를 통해 중심 단어를 예측하는 학습을 하게 됩니다. 윈도우를 계속 움직여 주변 단어와 중심 단어의 선택을 바꿔가며 학습하면 점점 단어들의 관계를 이해하게 되는 것이지요. 이때 이 워드투벡터의 학습 방법에 대해 알아보겠습니다. 우선 워드투벡터는 얕은 인공신경망 모델인데요, 인공신경망이란 인간의 뉴런에서 착안하여 만든 학습 알고리즘으로 겹겹이 쌓인 층으로 구성되어 있습니다. 층은 크게 입력값이 들어가는 입력층, 출력값이 나오는 출력층, 그리고 그 사이에 입력값들이 변환되는 은닉층(hidden layer) 세 가지로 구분할 수 있는데요, 워드투벡터는 은닉층이 하나이기 때문에 얕은 인공신경망으로 분류됩니다. 이때 은닉층에 부여되는 벡터가 단어를 임베딩한 벡터가 되고 따라서 그것을 알아내는 것이 워드투벡터의 학습 과정입니다.
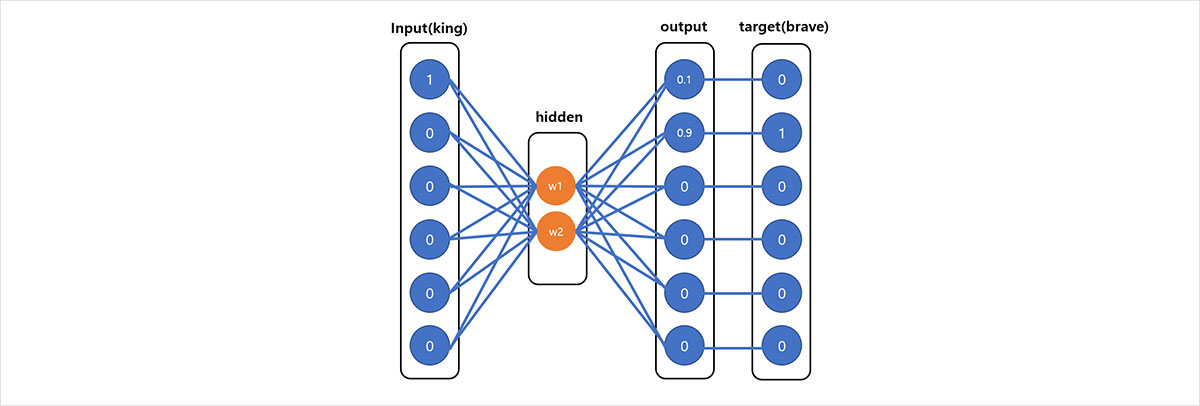
그림 4. 워드투벡터 인공 신경망 도식
그럼 앞선 예시로 돌아가 ‘king’이라는 단어를 워드투벡터를 통해 이차원 벡터로 임베딩 해보겠습니다. 우선 원-핫 코딩을 통해 ‘king’에 원-핫 벡터를 부여하면 [1,0,0,0,0,0]이 됩니다. 다음으로 은닉층에 벡터는 일단 무작위적으로 부여됩니다. 예를 들면, 처음에 은닉층에 임의의 벡터가 부여되어 그림4와 같이 출력층에 [0.1,0.9,0,0,0,0]가 출력되었다고 합시다. 그러면 ‘king’의 주변 단어였던 ‘brave’의 원-핫 벡터와 출력된 벡터를 비교하여 차이를 계산할 수 있고, 계산된 차이에 따라 은닉층에 부여된 벡터를 조정하게 됩니다. 이러한 과정을 인공신경망의 역전파(backpropagation)라 부르며, 역전파 과정을 반복하여 중심단어와 주변단어의 차이가 최소화되는 방향으로 점차 은닉층의 벡터가 조정되는 것입니다.
-
 그림 5. [그림3]의 워드투벡터 임베딩 결과
그림 5. [그림3]의 워드투벡터 임베딩 결과 -
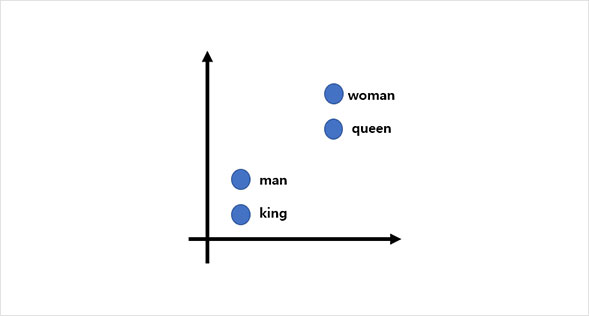 그림 6. 단어 사이의 유사도 파악
그림 6. 단어 사이의 유사도 파악
워드투벡터 과정을 거치면 최종적으로 [그림5]와 같이 단어를 이차원의 벡터로 임베딩 할 수 있습니다. 이 벡터를 [그림6]과 같은 이차원 그래프로 시각화하면 단어들의 유사도를 인지할 수 있습니다. 그림에서 확인할 수 있듯이 “man”과 “king”이 그리고 “woman”과 “queen”이 비슷한 곳에 위치해 있는 것을 볼 수 있고 이는 두 단어 사이에 유사도가 있다는 것을 의미합니다. 워드투벡터 과정을 통해 언어를 임베딩하여 컴퓨터에 입력하면 비로소 컴퓨터가 단어와 단어 사이의 관계, 즉 문맥을 이해할 수 있게 되는 것입니다.
지금까지 자연어 처리의 한 갈래로 원-핫 인코딩과 그것을 보완한 워드투벡터에 대해 알아보았습니다. 물론 워드투벡터도 자연어를 처리하는 데 한계를 가지는데요, 대표적으로 워드투벡터는 동일한 단어를 동일한 벡터로 임베딩하기에 동음이의어를 구분할 수 없는 단점이 있습니다. 이러한 단점을 보완하기 위해서 최근에는 자연어 처리 학습 모델이 단어를 입력받는 것에서 문장 전체를 입력받고 단어를 예측하는 것으로 발전하여 연구되고 있습니다. 인간과 컴퓨터가 완전하게 소통할 수 있는 때가 올 수 있을까에 대한 의문은 여전히 남아있지만, 이미 대화는 시작되었고 그 소통이 점점 원활해지고 있는 것만은 사실입니다.
지금까지 자연어 처리의 한 갈래로 원-핫 인코딩과 그것을 보완한 워드투벡터에 대해 알아보았습니다. 물론 워드투벡터도 자연어를 처리하는 데 한계를 가지는데요, 대표적으로 워드투벡터는 동일한 단어를 동일한 벡터로 임베딩하기에 동음이의어를 구분할 수 없는 단점이 있습니다. 이러한 단점을 보완하기 위해서 최근에는 자연어 처리 학습 모델이 단어를 입력받는 것에서 문장 전체를 입력받고 단어를 예측하는 것으로 발전하여 연구되고 있습니다. 인간과 컴퓨터가 완전하게 소통할 수 있는 때가 올 수 있을까에 대한 의문은 여전히 남아있지만, 이미 대화는 시작되었고 그 소통이 점점 원활해지고 있는 것만은 사실입니다.
- 참고자료
- [1] 위혜영, 「언어 능력과 자연어 처리: 자연인가 경험인가?」, 『인문언어』21권2호, 2019
- [2] 유승의, 「인공지능과 자연어 처리 기술 동향」, 2021.2.17
- [3] IDreamgonfly’s blog, 워드투벡터, dreamgonfly.github.io/blog/word2vec-explained, 2021.10.21
- [4] 유튜브, word2vec, www.youtube.com/watch?v=sY4YyacSsLc, 2021.10.21
- 그림 출처
- 그림3,4,5,6) 유튜브, word2vec, www.youtube.com/watch?v=sY4YyacSsLc, 2021.10.21/참조하여 새롭게 제작