나만의 얼굴 인식 프로그램 만들기
어느새 얼굴 인식 기술은 우리 생활 곳곳에서 활용되고 있습니다. 액션 영화 속 범인을 추적하는 데 사용되어 긴박한 상황을 그리기도 하고(그림1), 공항 입국 심사대나 휴대전화 잠금 화면 등 본인 인증이 필요한 일상에서도 사용됩니다(그림2). 카메라 애플리케이션인 '스노우(SNOW)'와 같이 얼굴 인식 스티커나 뷰티 필터가 지원되는 서비스도 얼굴 인식 서비스와 밀접하게 관련되어 있습니다. 모두 주어진 이미지에서 사람의 얼굴을 찾아내고 그 얼굴에서 특징을 추출해 내는 기술에 기반하고 있기 때문입니다.


그렇다면 이런 서비스들은 어떤 과정을 거쳐 사람의 얼굴을 인식할 수 있는 걸까요? 얼굴 인식 기술은 보통 다음과 같이 세 단계로 이루어집니다.
첫째, 얼굴 탐지 단계입니다. 이미지가 주어졌을 때, 사람의 얼굴이 어디에 존재하는지 찾아내는 역할을 수행합니다. 이때 이미지에는 사람이 한 명도 없을 수도 있고, 아주 많을 수도 있습니다. 앞서 본 영화의 한 장면처럼 아주 많은 사람이 나오는 동영상에서 얼굴 탐지를 수행할 때는 초당 수십 프레임(순간 이미지)을 분석해야 하기 때문에 매우 오랜 시간이 걸릴 수도 있습니다. 얼굴이 존재하는 영역은 박스라고 부르는데, 보통 박스는 직사각형이기 때문에 박스 모서리의 좌표를 다음 단계로 전달해주는 경우가 많습니다.
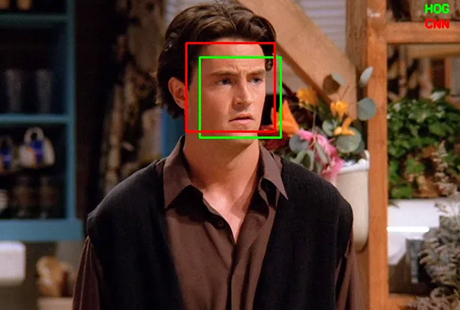

둘째, 특징 추출 단계입니다. 얼굴의 특징적인 요소들(눈, 코, 입 등)의 위치와 형태를 여러 점을 이용해 나타냅니다. 이런 점들을 랜드마크(Landmark)라고 부르는데, 랜드마크의 상대적인 위치와 배열은 사람마다 고유한 특징으로서 벡터1) 형태로 전달되어 서로 다른 사람임을 확인할 수 있게 해줍니다. 경우에 따라서는 얼굴 인식의 품질을 높이기 위해 랜드마크의 위치를 이용. 회전이나 비율 조정 등 전 처리를 수행하기도 합니다.
셋째, 식별 단계입니다. 새롭게 추출된 특징점(랜드마크)들의 벡터 정보를 데이터베이스와 비교합니다. 이때 두 벡터 간의 거리나 코사인 유사도2) 등을 이용하면, 새롭게 추출된 벡터와 가장 유사한 벡터를 찾아 그 벡터의 주인을 우리가 찾고자 했던 얼굴의 주인으로 추정할 수 있습니다.

여기까지 얼굴 인식의 원리에 대해 알아보았습니다! 다들 이해하셨나요? 지금부터는 앞서 설명한 세 단계에 맞추어, 파이썬의 face_recognition 라이브러리3)를 이용한 이미지 속 얼굴 인식을 함께 실습해봅시다!
우선 코딩을 시작하기에 앞서 필요한 라이브러리를 설치해야 합니다. 본 기사에서는 Python 3.10이 설치된 Linux 환경(Ubuntu 22.04 LTS)에서 코딩을 진행했습니다. 본 실습의 핵심이 되는 face_recognition 라이브러리를 터미널4)에서 다음과 같이 설치해줍니다.
pip install face_recognition face_recognition_models
만약 Google Colab을 이용해 실습할 경우, 터미널 명령어를 작동하기 위해서는 앞에 느낌표가 필요하기 때문에, !pip install face_recognition과 같이 맨 앞에 느낌표를 붙여주세요!
첫 번째로 얼굴 탐지를 수행해보겠습니다(코드1). 우선 이미지 처리에 사용되는 라이브러리인 Pillow(PIL)와 앞서 설치한 face_recognition 라이브러리를 불러옵니다.
from PIL import Image, ImageDraw import face_recognition
locate 메소드는 사진 픽셀 값들의 배열(img_array)을 변수로 받아, face_recognition 라이브러리의 face_locations 메소드를 이용해 얼굴을 탐지하고 그 좌표를 뽑아내는 것이 핵심입니다. 여기서는 face_locations 라는 이름의 변수에 탐지된 얼굴들의 좌표를 리스트 형태로 저장했습니다.
여기서 잠깐!
이때 use_gpu는 GPU 사용 여부에 관한 변수로서, True일 경우 GPU를 이용해 CNN 모델5)로 얼굴을 탐지하도록 만들었습니다. CNN 모델을 CPU만으로도 사용할 수는 있지만, 처리할 파일이 많아지면 매우 오래 걸릴 수 있기 때문에 GPU 환경에서 사용할 것을 추천합니다. use_gpu가 False일 때는 CNN 모델 대신 dlib 라이브러리의 HOG 모델6)로 얼굴을 탐지합니다. 다만 GPU를 사용하려면 CUDA, CUDA Toolkit, cuDNN을 상호 호환되는 버전으로 설치하고, dlib 라이브러리를 불러온 후 dlib.DLIB_USE_CUDA 값을 출력시켜 True가 반환되는지 확인해야 합니다!
if(use_gpu):
face_locations = face_recognition.face_locations(img_array, number_of_times_to_upsample=0, model="cnn")
else:
face_locations = face_recognition.face_locations(img_array)
print("File name : {} | # of faces found : {}".format(name, len(face_locations)))
그런 다음 얼굴 탐지 결과물을 출력합니다. draw_box의 값이 True일 경우 원본 이미지에서 탐지된 얼굴을 흰색 박스로 표시하고, False일 경우 탐지된 얼굴을 자르는 방법으로 결과물을 확인할 수 있습니다.
if(draw_box):
face_image = Image.fromarray(img_array)
for face_location in face_locations:
top, right, bottom, left = face_location
shape = [(left, top), (right, bottom)]
draw = ImageDraw.Draw(face_image)
draw.rectangle(shape, outline="white", width=10)
face_image.show()
else:
for face_location in face_locations:
top, right, bottom, left = face_location
face_image = Image.fromarray(img_array[top:bottom, left:right])
face_image.show()
from PIL import Image, ImageDraw
import face_recognition
def locate(name, img_array, use_gpu=False, draw_box=True):
if(use_gpu):
face_locations = face_recognition.face_locations(img_array, number_of_times_to_upsample=0, model="cnn")
else:
face_locations = face_recognition.face_locations(img_array)
print("File name : {} | # of faces found : {}".format(name, len(face_locations)))
if(draw_box):
face_image = Image.fromarray(img_array)
for face_location in face_locations:
top, right, bottom, left = face_location
shape = [(left, top), (right, bottom)]
draw = ImageDraw.Draw(face_image)
draw.rectangle(shape, outline="white", width=10)
face_image.show()
else:
for face_location in face_locations:
top, right, bottom, left = face_location
face_image = Image.fromarray(img_array[top:bottom, left:right])
face_image.show()
locate 메소드는 코드 5와 같은 코드로 실행시킬 수 있습니다. 이때 _load_image 메소드는 파일명(name)을 받아 이미지의 픽셀 값 배열을 반환합니다. 여기서는 'Obama.jpeg' 파일이 저장된 위치는 이 파이썬 파일(코드)이 동작하는 위치와 동일해야 합니다. '그림6'과 '7'은 draw_box가 True일 때 오바마 美 전 대통령의 초상(Obama.jpeg)에 대해 각각 HOG 모델(CPU 이용), CNN 모델(GPU 이용)로 얼굴을 탐지한 결과입니다. draw_box가 False이면 '그림8', '9'와 같이 얼굴만 잘린 결과를 얻게 됩니다. HOG 모델(그림6, 8)과 CNN 모델(그림7, 9)의 분석 결과가 조금 다른 것이 느껴지나요? CNN 모델의 경우 사전에 학습시킨 인공신경망을 이용하는 만큼, 정해진 알고리즘에 따라 분석하는 HOG 모델에 비해 더 정확한 것을 알 수 있습니다.
def _load_image(name:str):
return face_recognition.load_image_file(name)
if __name__ == "__main__":
file = "Obama.jpeg"
img_array = _load_image(file)
locate(file, img_array, use_gpu=False, draw_box=False)
locate(file, img_array, use_gpu=True, draw_box=False)

(좌. HOG 모델, 우. CNN 모델)

(좌. HOG 모델, 우. CNN 모델)
다음은 얼굴 내 특징점(랜드마크) 탐지 및 추출입니다. face_recognition 라이브러리의 face_landmarks 메소드를 이용하면, 주어진 사진 픽셀 값들의 배열(img_array)에 대해 얼굴의 특징점들을 추출할 수 있습니다. '코드6'의 landmarks 메소드는 face_landmarks 메소드를 이용해 얼굴의 특징점을 추출하고, 해당 특징점을 빨갛게 표시하고 하얀 선으로 연결해 보여줍니다. 실행 결과는 '코드8' 및 '그림10'과 같습니다. 눈, 코, 입, 턱에서 총 68개의 특징점이 추출된 것을 확인할 수 있습니다.
def landmarks(name, img_array, only_points=False):
face_landmarks = face_recognition.face_landmarks(img_array)
print("File name : {} | # of faces found : {}".format(name, len(face_landmarks)))
face_image = Image.fromarray(img_array)
draw = ImageDraw.Draw(face_image)
for face_landmark in face_landmarks:
for facial_feature in face_landmark.keys():
print(" - Feature : {} | Points : {}".format(facial_feature, face_landmark[facial_feature]))
for facial_feature in face_landmark.keys():
if(not only_points):
draw.line(face_landmark[facial_feature], width=10)
for point in face_landmark[facial_feature]:
radius = 10
x,y = point
draw.ellipse((x-radius,y-radius,x+radius,y+radius), fill=(255,0,0))
face_image.show()
if __name__ == "__main__":
file = "Obama.jpeg"
img_array = _load_image(file)
locate(file, img_array, use_gpu=False, draw_box=False)


마지막으로 여러 얼굴을 비교해, 얼굴의 주인을 찾아내봅시다. 우선 벡터 계산을 위해 numpy 라이브러리를 추가로 불러옵니다.
from PIL import Image, ImageDraw import numpy as np import face_recognition
그다음, face_recognition 라이브러리의 face_encodings 메소드를 이용해 앞서 구한 특징점들에 관한 정보를 벡터 형태로 변환합니다. 앞서 불러온 numpy 라이브러리의 norm 메소드를 이용하면, 두 벡터의 거리를 편리하게 구할 수 있습니다. database를 통해 비교하고자 하는 얼굴들의 특징점에 관한 정보를 모아 전달하면, guess 메소드는 database의 원소 벡터 하나하나와 새로운 사진 속 얼굴의 특징점 벡터(target) 간 거리를 비교하는 역할을 합니다.
def guess(name, img_array, database):
target = face_recognition.face_encodings(img_array)[0]
values = np.linalg.norm(database - target, axis=1)
return values
'코드11'과 같이 다섯 미국 전 대통령의 초상에서 추출한 얼굴 데이터를 database에 저장하고, 'Obama2.jpeg'라는 이름의 새로운 사진에 대해서 해당 사진 속 사람이 누구인지 식별해보았습니다.
if __name__ == "__main__":
files = ["Clinton.jpeg", "Bush.jpeg", "Obama.jpeg", "Trump.jpeg", "Biden.jpeg"]
unknown = "Obama2.jpeg"
database = [face_recognition.face_encodings(_load_image(file))[0] for file in files]
guessed = guess(unknown, _load_image(unknown), database)
print("File name : {} -> Guessed as : {}".format(unknown, files[np.argmin(guessed)]))
for i in range(len(files)):
print(" - {} | Distance : {}".format(files[i],guessed[i]))
실행 결과는 '코드12'와 같았습니다. 다섯 명 중에서 오바마 美 전 대통령의 얼굴과 가장 유사하다는(벡터 거리가 가장 작음) 결과가 나왔습니다. 정말 'Obama2.jpeg'는 오바마 전 대통령의 사진이었을까요?

'그림11' 하단의 이미지처럼, 'Obama2.jpeg'는 실제로 오바마 美 전 대통령의 사진이었습니다.

잘 이해하셨나요? 앞서 실습에서 사용한 face_recognition 라이브러리의 face_locations, face_landmarks, face_encodings 메소드를 잘 응용하면 실시간으로 웹캠과 연동되는 얼굴 인식 프로그램을 만들 수도 있고, 동일 인물의 사진을 여러 장 학습시켜 정확도를 높일 수도 있습니다. 간단하게는 벡터 간 거리(코드10) 대신 코사인 유사도를 이용해 유사성을 판단하도록 바꿔볼 수도 있고, 복잡하게는 기존 라이브러리에서 제공되는 얼굴의 특징점들을 추출하는 모델을 새롭게 만들어 적용해볼 수도 있겠습니다. 비록 실습 과정에서는 어떤 메소드가 어떻게 작동하는지 완벽하게 이해하지 못했더라도, 직접 face_recognition 라이브러리의 소스 코드를 하나씩 뜯어 보다 보면, 더욱 근사하고 완성도 높은 나만의 얼굴 인식 프로그램을 만들 수 있을 것입니다. 이번 코딩 실습을 통해, 여러분도 공학적인 사고와 탐구의 즐거움을 느꼈다면 좋겠습니다!
주석
1) 벡터: (컴퓨터과학) 1차원 배열의 데이터. 여기서는 실수로 이루어진 데이터를 의미한다.
2) 코사인 유사도: 두 벡터 간 각도의 코사인 값. 각도가 작을수록 코사인 값이 커져, 코사인 유사도가 커진다(최대 1).
3) 라이브러리: 재사용 가능한 코드의 모음. 대표적으로 행렬 계산에 자주 사용되는 numpy 라이브러리가 있다.
4) 터미널: 명령줄(텍스트)로 컴퓨터를 직접 제어하고 조작하기 위해 사용되는 프로그램. 대표적으로 윈도 운영체제의 명령 프롬프트(cmd)가 터미널에서 돌아간다.
5) CNN 모델: 합성곱 신경망. 이미지를 다루는 딥러닝(컴퓨터 비전)에서 자주 사용된다.
6) HOG 모델: 경사 지향 히스토그램. 이미지의 작은 부분에서 관찰된 윤곽선의 방향 및 gradient(경사)를 히스토그램으로 나타내 이미지의 특성을 나타낸다.
참고 문헌
Adam Geitgey, face_recognition. 2024, Github repository, https://github.com/ageitgey/face_recognition
Adrian Rosebrock, Face detection with dlib (HOG and CNN). 19 Apr 2021, pyimagesearch, https://pyimagesearch.com/2021/04/19/face-detection-with-dlib-hog-and-cnn/
그림 출처
그림1. 미션 임파서블: 데드 레코닝 (Part 1). Jul 2023.
그림2. Joe Rossignol, Under-Display Face ID on iPhone Still at Least Two Years Away, Says Analyst. 9 Mar 2023. https://www.macrumors.com/2023/03/09/under-display-face-id-2025-ross-young/
그림3. Arun Ponnusamy, CNN based face detector from dlib. 18 Apr 2018. https://towardsdatascience.com/cnn-based-face-detector-from-dlib-c3696195e01c
그림4. Face landmark detection guide. MediaPipe, 23 Jan 2024. https://developers.google.com/mediapipe/solutions/vision/face_landmarker
그림5. Brad Smith, Finally, progress on regulating facial recognition. 31 Mar 2020. https://blogs.microsoft.com/on-the-issues/2020/03/31/washington-facial-recognition-legislation/
그림11. Bill Clinton, George W. Bush, Barack Obama, Donald Trump, and Joe Biden. Wikipedia, Accessed 8 Feb 2024. https://en.wikipedia.org/wiki/Bill_Clinton, https://en.wikipedia.org/wiki/George_W._Bush, https://en.wikipedia.org/wiki/Barack_Obama, https://en.wikipedia.org/wiki/Donald_Trump, and https://en.wikipedia.org/wiki/Joe_Biden.