


그림 1, 2. 강아지 그림
이번 기사는 귀여운 강아지 그림 두 장으로 시작해보려 합니다!
두 그림 모두 보기 좋네요. 왼쪽 그림은 성운과 강아지를 결합한 디지털 아트이고, 오른쪽은 베레모를 쓴 강아지를 그려낸 실사화로군요.
그런데, 두 그림이 사람이 그린 그림이 아니라는 사실이 믿겨지시나요? 이 그림들은 DALL-E 2라는 놀라운 인공지능이 그린 그림입니다!
DALL-E는 CLIP, GPT-3 등의 인공지능 모델을 개발한 OpenAI라는 기업에서 제작된 화가 인공지능입니다. DALL-E에 그림을 묘사하는 간단한 문장을 입력하면 그에 해당하는 그림 몇 가지를 1분도 안 되는 시간에 얻을 수 있습니다. 예를 들어, ‘아보카도 의자’를 입력하면:
두 그림 모두 보기 좋네요. 왼쪽 그림은 성운과 강아지를 결합한 디지털 아트이고, 오른쪽은 베레모를 쓴 강아지를 그려낸 실사화로군요.
그런데, 두 그림이 사람이 그린 그림이 아니라는 사실이 믿겨지시나요? 이 그림들은 DALL-E 2라는 놀라운 인공지능이 그린 그림입니다!
DALL-E는 CLIP, GPT-3 등의 인공지능 모델을 개발한 OpenAI라는 기업에서 제작된 화가 인공지능입니다. DALL-E에 그림을 묘사하는 간단한 문장을 입력하면 그에 해당하는 그림 몇 가지를 1분도 안 되는 시간에 얻을 수 있습니다. 예를 들어, ‘아보카도 의자’를 입력하면:

그림 3. DALL-E에 “아보카도 의자”를 입력하여 얻을 수 있는 이미지
그림 3과 같이 정말 다양하고 창의적인 이미지들이 나타납니다. 마치 실물 사진 같지만, 모두 DALL-E가 처음부터 창작해낸 그림입니다.
지난 해 4월 13일에는 후속작 DALL-E 2가 발표되었습니다. 기존보다 4배 향상된 화질로 이미지를 만들어낼 수 있게 되었으며, 그 결과물들은 훨씬 자연스러워졌습니다. 위의 두 강아지 이미지도 DALL-E 2의 결과물입니다.
또, DALL-E 2가 그림만 그릴 수 있는 것은 아닙니다. 이미지의 크기를 키우거나 서로 다른 그림을 합칠 수 있고, 기존에는 어려웠던 그림체를 바꾸는 기술도 가지고 있습니다.
지난 해 4월 13일에는 후속작 DALL-E 2가 발표되었습니다. 기존보다 4배 향상된 화질로 이미지를 만들어낼 수 있게 되었으며, 그 결과물들은 훨씬 자연스러워졌습니다. 위의 두 강아지 이미지도 DALL-E 2의 결과물입니다.
또, DALL-E 2가 그림만 그릴 수 있는 것은 아닙니다. 이미지의 크기를 키우거나 서로 다른 그림을 합칠 수 있고, 기존에는 어려웠던 그림체를 바꾸는 기술도 가지고 있습니다.

그림 4. DALL-E 2에 <진주 귀고리를 한 소녀> 그림을 입력하고, 그림체를 바꾼 결과
그림 4는 한 명화를 기반으로 DALL-E 2가 새로운 그림을 창작해낸 예시입니다.
인공지능이 했다고 믿기 어려울 정도의 놀라운 결과입니다. 대체 이런 결과물이 어떻게 나타나는 것일까요? 지금부터 자세히 알아보겠습니다.
인공지능이 했다고 믿기 어려울 정도의 놀라운 결과입니다. 대체 이런 결과물이 어떻게 나타나는 것일까요? 지금부터 자세히 알아보겠습니다.
인공지능의 기본적 원리
인공지능은 인간을 모방하기 위해 만들어진 객체입니다. 언뜻 들어서는 제작하기 그리 어렵지 않아 보입니다. 그러나, 기존의 개발 방식은 컴퓨터가 인간이 맞닥뜨리는 상황에 대처하기 위해 발생 가능한 모든 상황을 개발자가 직접 입력해 두어야 했습니다. 현실 세계에서 일어날 수 있는 무수히 많은 경우의 수를 고려해 보았을 때, 이는 사실상 불가능합니다. 이 문제점을 해결하기 위해 등장한 방안이 ‘인공 신경망’ 입니다.
인공지능은 인간을 모방하기 위해 만들어진 객체입니다. 언뜻 들어서는 제작하기 그리 어렵지 않아 보입니다. 그러나, 기존의 개발 방식은 컴퓨터가 인간이 맞닥뜨리는 상황에 대처하기 위해 발생 가능한 모든 상황을 개발자가 직접 입력해 두어야 했습니다. 현실 세계에서 일어날 수 있는 무수히 많은 경우의 수를 고려해 보았을 때, 이는 사실상 불가능합니다. 이 문제점을 해결하기 위해 등장한 방안이 ‘인공 신경망’ 입니다.

그림 5. 인공신경망의 구조
인공신경망은 실제 동물들의 신경세포(뉴런) 구조를 모방하여 만들어졌습니다. 뉴런은 자신과 붙어있는 다른 뉴런들이 전달한 정보를 종합한 신호를 다시 전달하는데1, 인공신경망도 비슷합니다. 가장 단순한 인공신경망은 그림 5와 같은 형태로서, 입력부와 출력부, 그리고 이를 이어주는 선분들로 이루어져 있습니다. 입력부의 각 노드(Node)2는 입력의 조건을 의미합니다. 인공신경망은 입력에 따라 각 노드에 값을 배정합니다. 예를 들어, 신경망에서 입력받은 값이 미리 정해진 조건을 만족하면 노드에 특정 수를 적고, 만족하지 않으면 0을 적는 방법을 생각해 볼 수 있습니다. 출력부에서는 입력부의 각 노드에 적힌 값을 모두 더해서 그 결과에 따라 출력할 값을 결정합니다.
1 이를 시냅스합이라고 부릅니다.
2 그림 5에서 원 모양으로 그려져 있는 것들을 노드라고 부릅니다.
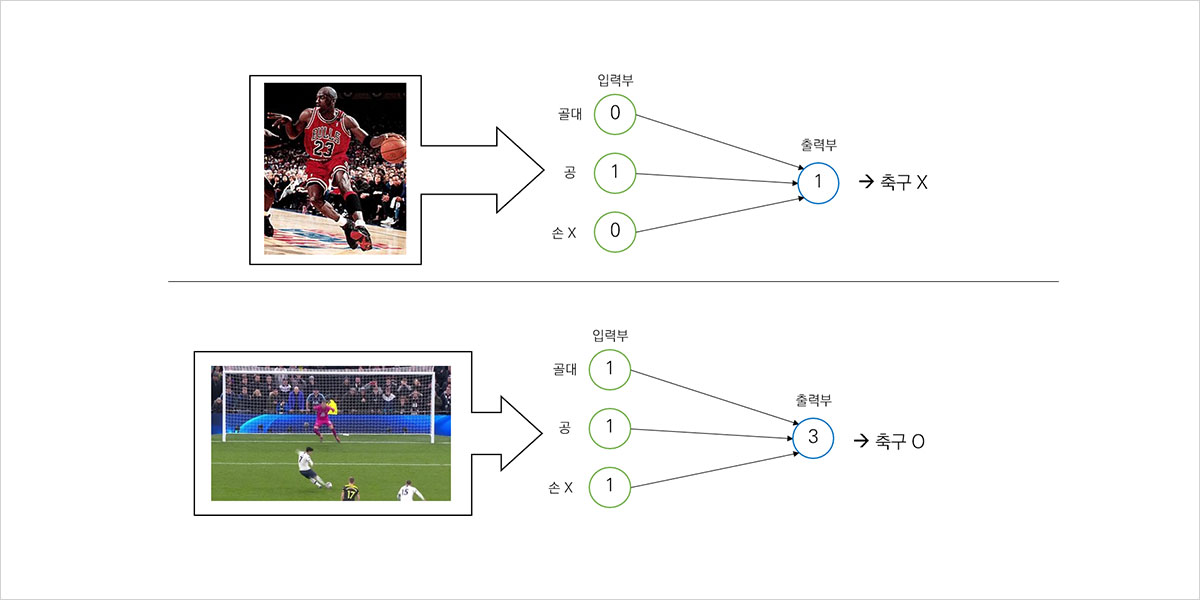
그림 6. 예시 신경망: 축구 판별
예를 들어, 그림 6과 같이 어느 사진이 축구 경기를 찍은 사진인지 아닌지를 구별하는 인공신경망을 만들었다고 생각해봅시다. 이 경우에는 입력부의 노드를 ‘골대가 있는가?’, ‘공이 있는가?’, ‘공을 손에 들고 있지 않은가?’ 등의 조건에 대응시킵시다. 입력된 사진이 각 조건을 만족시키면 노드에 1을 적고, 만족시키지 않으면 0을 적는 것으로 한 뒤, 입력부에 적힌 값의 총합이 3 이상이면 출력부에서 이 사진이 축구경기가 맞다고 판정하면 됩니다. 우리는 인공지능을 만들었습니다! 기존에는 인공지능을 만들기 위해 이미지의 다양한 특징들이 만들 수 있는 무수히 많은 경우의 수를 모두 고려해야 했습니다. 하지만 인공지능을 이용하면 오직 3개의 질문에만 대답해도 사진을 분류할 수 있습니다. 훨씬 간단하죠?
이렇게 만들어진 신경망에 그림 6과 같이 마이클 조던이 드리블을 하는 이미지를 입력하면 축구가 아니라고 판별하고, 손흥민이 프리킥을 하는 이미지를 입력하면 축구라고 판별하게 됩니다.
앞에서 만든 인공신경망을 더 개선해 봅시다. 각 조건마다 중요도가 있지 않나요? 위에서 말한 ‘공이 있는가?’와 같은 조건은 농구, 배구, 골프 등 수많은 경기와 겹치는 조건입니다. 그에 반해 ‘골대가 있는가?’는 축구에만 해당하는 조건이기 때문에 후자가 전자에 비해 더 중요한 조건이라고 할 수 있습니다. 어떤 조건은 다른 조건보다 더욱 중요하고, 어떤 조건은 덜 중요하겠지요. 이러한 중요도를 반영하는 방법은 꽤 간단한데, 가중치를 주면 됩니다. 가령 골대를 2배로 더 중요하게 고려하고 싶다면 골대 조건에 해당하는 노드에 적힌 값에는 항상 2를 곱해서 결과치에 더하는 식으로 신경망을 만드는 것이죠.
이제 입력부를 아주 크게 만들고, 그리고 신경망의 각 출력이 다시 입력이 되도록 만들어서 입력부와 출력부 사이에 노드로 이루어진 여러 층을 쌓으면 실제 인공지능에 사용할 수 있을 만큼 복잡한 신경망을 만들 수 있습니다.3
이후 각각의 노드들에 대해 가중치, 즉 중요도를 배정하면 끝납니다. 인공지능을 ‘학습시킨다’ 라는 용어를 자주 본 적이 있을 텐데, 바로 이 가중치를 배정하는 과정이 학습입니다. 결과물을 잘 맞히는 좋은 가중치를 얻을 때까지 계속해서 스스로를 개선해 나가는 것입니다.4 이것이 인공지능의 기본적 구조입니다.
이렇게 만들어진 신경망에 그림 6과 같이 마이클 조던이 드리블을 하는 이미지를 입력하면 축구가 아니라고 판별하고, 손흥민이 프리킥을 하는 이미지를 입력하면 축구라고 판별하게 됩니다.
앞에서 만든 인공신경망을 더 개선해 봅시다. 각 조건마다 중요도가 있지 않나요? 위에서 말한 ‘공이 있는가?’와 같은 조건은 농구, 배구, 골프 등 수많은 경기와 겹치는 조건입니다. 그에 반해 ‘골대가 있는가?’는 축구에만 해당하는 조건이기 때문에 후자가 전자에 비해 더 중요한 조건이라고 할 수 있습니다. 어떤 조건은 다른 조건보다 더욱 중요하고, 어떤 조건은 덜 중요하겠지요. 이러한 중요도를 반영하는 방법은 꽤 간단한데, 가중치를 주면 됩니다. 가령 골대를 2배로 더 중요하게 고려하고 싶다면 골대 조건에 해당하는 노드에 적힌 값에는 항상 2를 곱해서 결과치에 더하는 식으로 신경망을 만드는 것이죠.
이제 입력부를 아주 크게 만들고, 그리고 신경망의 각 출력이 다시 입력이 되도록 만들어서 입력부와 출력부 사이에 노드로 이루어진 여러 층을 쌓으면 실제 인공지능에 사용할 수 있을 만큼 복잡한 신경망을 만들 수 있습니다.3
이후 각각의 노드들에 대해 가중치, 즉 중요도를 배정하면 끝납니다. 인공지능을 ‘학습시킨다’ 라는 용어를 자주 본 적이 있을 텐데, 바로 이 가중치를 배정하는 과정이 학습입니다. 결과물을 잘 맞히는 좋은 가중치를 얻을 때까지 계속해서 스스로를 개선해 나가는 것입니다.4 이것이 인공지능의 기본적 구조입니다.
3 예리한 독자분들이라면 눈치채셨겠지만, 사실 이런 형태의 신경망은 깊게 만들어도 한 층으로 압축할 수 있기 때문에 큰 의미는 없습니다. 실제로는 단순히 합치는 것이 아니라, 합쳐진 값에 특정한 함수를 적용함으로서 더 복잡한 인간의 사고를 구현해낸답니다.
4 자세한 과정이 궁금하다면 ‘경사 하강법’, ‘역 전파’에 대해 공부해 보세요.
DALL-E 2의 구조 파헤치기

그림 7. DALL-E 2의 구조 모식도
이제 DALL-E 2의 구조에 대해 알아보겠습니다. 그림 7은 DALL-E 2의 구조를 시각화한 것인데요, DALL-E 2도 다른 인공지능과 마찬가지로 신경망 기술을 활용해 만들어졌음을 알 수 있습니다. 그림 7의 점선 위쪽 부분은 이미 존재하는 온라인 상의 이미지를 컴퓨터도 이해할 수 있는 형태로 바꾸는 과정입니다. 점선 아래쪽 부분은 DALL-E 2가 실제로 사용자가 입력한 문장을 받아서 이미지를 생성할 수 있도록 신경망을 학습시키는 과정입니다.
구조가 간단해 보이지만, 사실 DALL-E 2는 매우 복잡하고 정교하게 구성되어 있습니다. 우선, DALL-E 2의 입력부는 총 1280개이며, 사용자에게 이미지와 문장을 입력받을 수 있습니다. 이미지는 가로, 세로 각각 32조각으로 나누어 총 1024개의 입력부에 대입되고, 문장도 총 256조각으로 나뉘어 256개의 입력부에 대입됩니다. 입력부가 거대한 만큼 신경망의 전체 크기도 매우 거대한데요, DALL-E 2 신경망 내부에 있는 변수(가중치)의 개수는 무려 35억개가 넘습니다. 즉, DALL-E 2는 문장과 이미지를 잘게 쪼개고, 각각에 조각에서 얻을 수 있는 정보들을 매우 복잡한 방식으로 종합해서 결과물을 내놓는 것입니다. 하지만, 기본 원리 자체는 그림 6의 축구 인공지능과 크게 다르지 않습니다.
구조가 간단해 보이지만, 사실 DALL-E 2는 매우 복잡하고 정교하게 구성되어 있습니다. 우선, DALL-E 2의 입력부는 총 1280개이며, 사용자에게 이미지와 문장을 입력받을 수 있습니다. 이미지는 가로, 세로 각각 32조각으로 나누어 총 1024개의 입력부에 대입되고, 문장도 총 256조각으로 나뉘어 256개의 입력부에 대입됩니다. 입력부가 거대한 만큼 신경망의 전체 크기도 매우 거대한데요, DALL-E 2 신경망 내부에 있는 변수(가중치)의 개수는 무려 35억개가 넘습니다. 즉, DALL-E 2는 문장과 이미지를 잘게 쪼개고, 각각에 조각에서 얻을 수 있는 정보들을 매우 복잡한 방식으로 종합해서 결과물을 내놓는 것입니다. 하지만, 기본 원리 자체는 그림 6의 축구 인공지능과 크게 다르지 않습니다.
DALL-E 2로 그림 만들기 1단계: 문장 이해하기
우리가 실제로 어떤 문장을 읽고 그림을 그리려 하는 상황을 생각해 봅시다. 그림을 그리기 위해서는 우선 문장을 읽고 이해해야 하며, 그 문장에 맞는 그림에 대한 아이디어를 생각하고, 우리가 지금까지 살면서 직접 보고 배운 형태들을 적절히 조합해서 아이디어를 그림으로 구현해내야 합니다. 이들은 모두 정말 어려운 문제입니다.
첫 단계로, 컴퓨터가 문장을 이해한다는 것은 매우 어렵습니다. 수많은 단어들을 모두 기억하고, 이들의 문맥상 의미를 모두 파악해야 하며, 그 의미들을 적절히 종합해야 하기 때문입니다. 그래서 사람들은 이 문제를 단순화시킬 방법들을 많이 연구했는데, 그 중 하나가 ‘임베딩’(Embedding) 입니다. 임베딩이란, 어떤 객체들(특히 단어와 같은 것들)을 N차원 좌표로 대응시키는 것입니다. 두 객체가 비슷하다면 대응된 좌표의 값이 가깝고, 차이가 있다면 대응된 좌표의 값이 멀도록 임베딩해봅시다. 그렇다면, 상술한 문제는 입력된 문장의 좌표와 가장 가까운 좌표에 존재하는 그림을 출력함으로써 곧바로 풀 수 있게 됩니다.
DALL-E 2는 이 아이디어를 차용하여 만든 CLIP이라는 인공지능 모델을 활용합니다. CLIP은 이미지와 문장을 입력으로 받아서, 문장이 이미지를 잘 설명할수록 작은 값을 내놓습니다. (좌표 간의 거리가 작다는 뜻이지요) CLIP의 원리에도 임베딩이 숨어 있습니다. CLIP은 이미지와 그에 맞는 올바른 설명이 달린 문장이 묶인 데이터 쌍을 수억 개 학습했습니다. 이를 기반으로 CLIP은 이미지와 문장을 모두 같은 평면에 임베딩하는데, 의미가 가까운 것끼리는 서로 가까운 좌표에, 의미가 먼 것끼리는 서로 먼 좌표에 대응합니다. 이제 CLIP에 이미지-문장 쌍을 입력하면 CLIP은 이미지와 문장을 모두 좌표평면으로 옮기고, 두 객체 사이의 거리를 구해서 출력합니다.
우리가 실제로 어떤 문장을 읽고 그림을 그리려 하는 상황을 생각해 봅시다. 그림을 그리기 위해서는 우선 문장을 읽고 이해해야 하며, 그 문장에 맞는 그림에 대한 아이디어를 생각하고, 우리가 지금까지 살면서 직접 보고 배운 형태들을 적절히 조합해서 아이디어를 그림으로 구현해내야 합니다. 이들은 모두 정말 어려운 문제입니다.
첫 단계로, 컴퓨터가 문장을 이해한다는 것은 매우 어렵습니다. 수많은 단어들을 모두 기억하고, 이들의 문맥상 의미를 모두 파악해야 하며, 그 의미들을 적절히 종합해야 하기 때문입니다. 그래서 사람들은 이 문제를 단순화시킬 방법들을 많이 연구했는데, 그 중 하나가 ‘임베딩’(Embedding) 입니다. 임베딩이란, 어떤 객체들(특히 단어와 같은 것들)을 N차원 좌표로 대응시키는 것입니다. 두 객체가 비슷하다면 대응된 좌표의 값이 가깝고, 차이가 있다면 대응된 좌표의 값이 멀도록 임베딩해봅시다. 그렇다면, 상술한 문제는 입력된 문장의 좌표와 가장 가까운 좌표에 존재하는 그림을 출력함으로써 곧바로 풀 수 있게 됩니다.
DALL-E 2는 이 아이디어를 차용하여 만든 CLIP이라는 인공지능 모델을 활용합니다. CLIP은 이미지와 문장을 입력으로 받아서, 문장이 이미지를 잘 설명할수록 작은 값을 내놓습니다. (좌표 간의 거리가 작다는 뜻이지요) CLIP의 원리에도 임베딩이 숨어 있습니다. CLIP은 이미지와 그에 맞는 올바른 설명이 달린 문장이 묶인 데이터 쌍을 수억 개 학습했습니다. 이를 기반으로 CLIP은 이미지와 문장을 모두 같은 평면에 임베딩하는데, 의미가 가까운 것끼리는 서로 가까운 좌표에, 의미가 먼 것끼리는 서로 먼 좌표에 대응합니다. 이제 CLIP에 이미지-문장 쌍을 입력하면 CLIP은 이미지와 문장을 모두 좌표평면으로 옮기고, 두 객체 사이의 거리를 구해서 출력합니다.
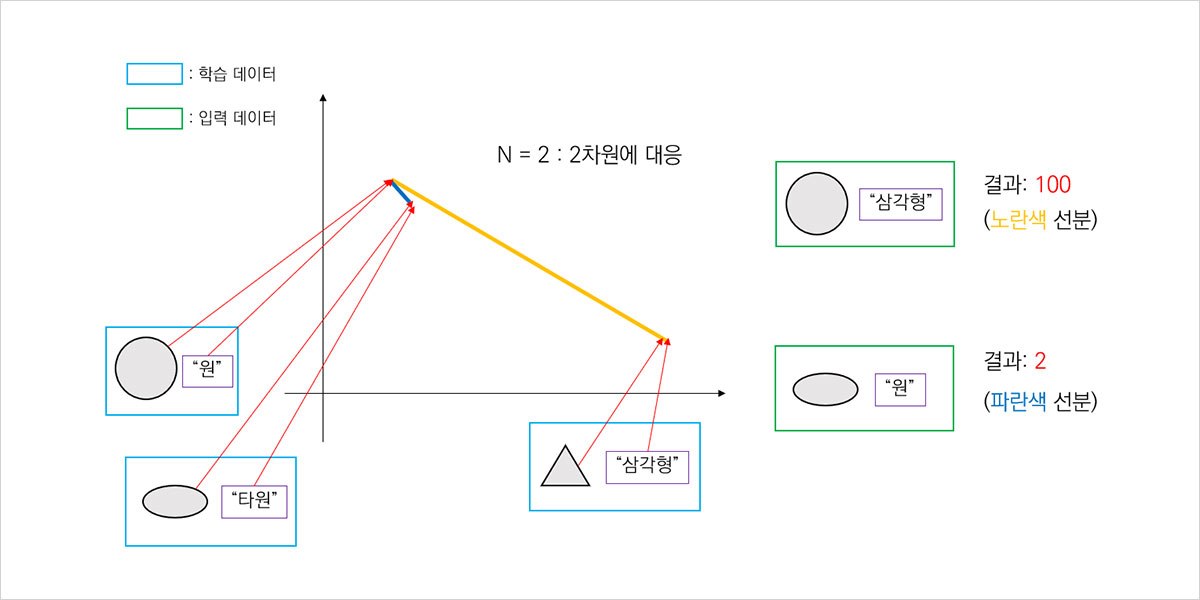
그림 8. CLIP의 작동 예시
예를 들어, CLIP이 이미지와 텍스트 쌍을 2차원 평면에 대응한다고 해 보겠습니다. 그림 8과 같이, CLIP은 특정 이미지와 그에 맞는 설명(문장)을 받아 훈련합니다. 평면에 원과 타원처럼 의미가 가까운 단어들은 가깝게, 원과 삼각형처럼 의미가 먼 단어들은 멀게 대응하는 것입니다.5
잘 훈련된 CLIP에 직접 입력을 넣어 보겠습니다. 그림 8의 초록색 사각형으로 묶인 (그림, 문장) 쌍이 각각의 입력에 대응됩니다. 예를 들어 원이 그려진 이미지와 ‘삼각형’이라는 문장을 넣으면 CLIP은 각각에 대응되는 좌표를 찾아서 거리를 구합니다. 이 경우에는 원의 특징을 ‘삼각형’이 잘 설명하지 못하기 때문에 거리가 크게 나타납니다. 그와 반대로 의미가 가까운 타원 이미지와 문장 ‘원’은 거리가 작게 나타납니다.
여기까지의 내용이 그림 7의 점선 위쪽 부분에 해당됩니다. Image Encoder와 Text Encoder가 각각 이미지와 문장을 임베딩하기 위해 특정 규칙을 가지고, 이들을 N차원 좌표로 인코딩6하는 역할을 합니다. 작은 정사각형은 좌표의 각 성분을 의미합니다. 이러한 CLIP 인공지능의 가동은 한 번이면 충분합니다. 이미 대응한 이미지들을 다시 대응시킬 필요는 없으니까요.
잘 훈련된 CLIP에 직접 입력을 넣어 보겠습니다. 그림 8의 초록색 사각형으로 묶인 (그림, 문장) 쌍이 각각의 입력에 대응됩니다. 예를 들어 원이 그려진 이미지와 ‘삼각형’이라는 문장을 넣으면 CLIP은 각각에 대응되는 좌표를 찾아서 거리를 구합니다. 이 경우에는 원의 특징을 ‘삼각형’이 잘 설명하지 못하기 때문에 거리가 크게 나타납니다. 그와 반대로 의미가 가까운 타원 이미지와 문장 ‘원’은 거리가 작게 나타납니다.
여기까지의 내용이 그림 7의 점선 위쪽 부분에 해당됩니다. Image Encoder와 Text Encoder가 각각 이미지와 문장을 임베딩하기 위해 특정 규칙을 가지고, 이들을 N차원 좌표로 인코딩6하는 역할을 합니다. 작은 정사각형은 좌표의 각 성분을 의미합니다. 이러한 CLIP 인공지능의 가동은 한 번이면 충분합니다. 이미 대응한 이미지들을 다시 대응시킬 필요는 없으니까요.
5 상세한 내용이 궁금하다면 이전 기사( http://beengineers.snu-eng.kr/html/2111/s0102.html )를 함께 읽어 보세요!
6 임베딩을 위해 우리가 원하는 모양대로 객체를 바꾸는 것을 “인코딩”(Encoding)이라고 합니다. 이 경우에는 문장과 이미지를 N차원 좌표 모양으로 바꾸었습니다.
DALL-E 2로 그림 만들기 2단계: 이미지 생성하기
이제부터는 그림 7의 점선 아래 부분을 관찰해 보겠습니다. 점선 윗부분에서 일어났던 변환이 반대 방향으로 이루어지고 있습니다. 실제로, DALL-E의 최종 결과물은 어떤 N차원 좌표나, 간단한 문장을 이미지로 디코딩7함으로서 얻어집니다. 더 자세하게 알아봅시다.
그림 7을 보면, 우리가 입력한 문장이 CLIP에서 문장을 대응하는 N차원 좌표(이하 문장 좌표)로 바뀝니다. 문장 좌표는 신경망(Prior)을 통과해서 CLIP에서 이미지를 대응하는 N차원 좌표(이하 이미지 좌표)로 바뀐 뒤, 다시 이미지 좌표가 디코딩되어 이미지로 바뀐다는 것을 알 수 있습니다. 여기에서 가장 중요한 과정이 중간의 Prior입니다. 이 과정을 거침으로서 DALL-E 2의 능력이 극대화되기 때문입니다.
Prior도 일종의 인공지능입니다. 문장 좌표를 넣으면 그에 알맞은 이미지 좌표를 출력하는 것이 목표이죠. 여기에서 또 ‘확산 모델’(Diffusion Model)이라는 새로운 개념이 등장합니다.
우리가 그림을 그릴 때, 조건이 많이 주어질수록 창의적인 그림을 그리기가 어렵습니다. 마찬가지로, 인공지능이 어떤 객체를 만들 때도 조건이 많은 것보다는 적은 것이 다양한 생성물을 만들기에 유리합니다. 확산 모델은 여기에서부터 출발합니다.
이제부터는 그림 7의 점선 아래 부분을 관찰해 보겠습니다. 점선 윗부분에서 일어났던 변환이 반대 방향으로 이루어지고 있습니다. 실제로, DALL-E의 최종 결과물은 어떤 N차원 좌표나, 간단한 문장을 이미지로 디코딩7함으로서 얻어집니다. 더 자세하게 알아봅시다.
그림 7을 보면, 우리가 입력한 문장이 CLIP에서 문장을 대응하는 N차원 좌표(이하 문장 좌표)로 바뀝니다. 문장 좌표는 신경망(Prior)을 통과해서 CLIP에서 이미지를 대응하는 N차원 좌표(이하 이미지 좌표)로 바뀐 뒤, 다시 이미지 좌표가 디코딩되어 이미지로 바뀐다는 것을 알 수 있습니다. 여기에서 가장 중요한 과정이 중간의 Prior입니다. 이 과정을 거침으로서 DALL-E 2의 능력이 극대화되기 때문입니다.
Prior도 일종의 인공지능입니다. 문장 좌표를 넣으면 그에 알맞은 이미지 좌표를 출력하는 것이 목표이죠. 여기에서 또 ‘확산 모델’(Diffusion Model)이라는 새로운 개념이 등장합니다.
우리가 그림을 그릴 때, 조건이 많이 주어질수록 창의적인 그림을 그리기가 어렵습니다. 마찬가지로, 인공지능이 어떤 객체를 만들 때도 조건이 많은 것보다는 적은 것이 다양한 생성물을 만들기에 유리합니다. 확산 모델은 여기에서부터 출발합니다.
7 Decoding, 인코딩의 역입니다. 이 경우에는 이미지의 정보가 담겨 있는 N차원 좌표를 이미지로 바꾸는 것이 되겠습니다.

그림 9. 확산 모델의 학습 과정
이미지를 점점 망치는 과정을 생각해 보겠습니다. 처음에는 조금씩 흐리게 보이다가, 나중에는 아예 식별이 불가능해질 것입니다. 확산 모델은 이 역과정을 시도합니다. 즉, 아예 아무것도 보이지 않는 흐린 화면에서부터 어떤 이미지를 제작하는 과정을 학습합니다. 마치 우리가 밑그림을 그리고 나서 제대로 된 그림을 그리듯, 확산 모델도 흐린 화면에서부터 시작해 새로운 이미지를 만듭니다. 이 방식은 무언가를 제작하는 인공지능(이미지, 소설 등)을 만들고자 할 때 거의 대부분의 상황에서 쓰일 수 있습니다. Prior은 이 확산 모델을 응용해서 만들어진 인공지능이며, 이미지 좌표를 결과값으로 생성합니다.
사실, 잘 생각해보면 굳이 Prior이라는 과정이 필요하지는 않습니다. 예를 들어, CLIP을 활용하면 곧바로 문장 좌표와 가장 가까운 이미지 좌표를 얻을 수도 있습니다. 하지만, Prior를 활용하지 않은 인공지능은 유연성이 훨씬 떨어집니다. 실제로 DALL-E 2의 연구진은 실제로 Prior를 포함하지 않은 DALL-E 2와 Prior을 포함한 DALL-E 2를 비교하였는데, Prior이 포함된 버전의 DALL-E 2가 훨씬 창의적이고 완성된 이미지를 출력한다는 것을 알 수 있었다고 합니다.
마지막으로, 이미지를 생성하는 디코더 또한 확산 모델을 응용하여 만들어졌습니다. 그런데, 사실 확산 모델은 이미지에 대해 아무것도 결정되지 않은 백지상태에서부터 시작합니다. 결과물의 형태가 전적으로 인공지능에게 맡겨지는 것입니다. 연구진은 GLIDE라는 확산 모델을 디코더에 적용했습니다. GLIDE는 이미지의 특징 몇 가지를 자연어8로 입력받고, 생성 모델이 이를 기반으로 이미지를 생성할 수 있도록 유도하는 인공지능 모델입니다. 연구진은 GLIDE가 처음에 DALL-E 2에 입력된 문장과, Prior에서 생성된 이미지 좌표까지 총 2가지를 이미지의 특성으로서 입력 받을 수 있도록 개선하여 디코더에 적용하였습니다. 이 디코더에서 나오는 최종 이미지가 DALL-E 2의 결과물이 됩니다.
사실, 잘 생각해보면 굳이 Prior이라는 과정이 필요하지는 않습니다. 예를 들어, CLIP을 활용하면 곧바로 문장 좌표와 가장 가까운 이미지 좌표를 얻을 수도 있습니다. 하지만, Prior를 활용하지 않은 인공지능은 유연성이 훨씬 떨어집니다. 실제로 DALL-E 2의 연구진은 실제로 Prior를 포함하지 않은 DALL-E 2와 Prior을 포함한 DALL-E 2를 비교하였는데, Prior이 포함된 버전의 DALL-E 2가 훨씬 창의적이고 완성된 이미지를 출력한다는 것을 알 수 있었다고 합니다.
마지막으로, 이미지를 생성하는 디코더 또한 확산 모델을 응용하여 만들어졌습니다. 그런데, 사실 확산 모델은 이미지에 대해 아무것도 결정되지 않은 백지상태에서부터 시작합니다. 결과물의 형태가 전적으로 인공지능에게 맡겨지는 것입니다. 연구진은 GLIDE라는 확산 모델을 디코더에 적용했습니다. GLIDE는 이미지의 특징 몇 가지를 자연어8로 입력받고, 생성 모델이 이를 기반으로 이미지를 생성할 수 있도록 유도하는 인공지능 모델입니다. 연구진은 GLIDE가 처음에 DALL-E 2에 입력된 문장과, Prior에서 생성된 이미지 좌표까지 총 2가지를 이미지의 특성으로서 입력 받을 수 있도록 개선하여 디코더에 적용하였습니다. 이 디코더에서 나오는 최종 이미지가 DALL-E 2의 결과물이 됩니다.
8 우리가 평소에 사용하는 언어, 즉 한국어, 영어와 같이 자연히 발생한 언어를 뜻해요!
DALL-E 2의 구조 정리하기
이제 DALL-E 2가 어떻게 학습되었는지를 다시 정리해 보겠습니다. 우선, CLIP이라는 독립적인 인공지능을 가져와서 이미지와 문장을 N차원 좌표계로 대응합니다. 그 과정에서 그림과 문장의 유사도를 쉽게 알 수 있게 됩니다. 이후 DALL-E 2는 자신에게 입력된 문장을 문장 좌표로 바꾸고, 이를 Prior에 통과시켜 이미지 좌표를 만듭니다. 이 이미지 좌표는 최종적으로 이미지를 제작하는 디코더에 맨 처음 입력된 문장과 함께 입력되고, 우리가 원하는 이미지가 출력되는 것입니다. DALL-E 2는 여러 기존 인공지능 모델들과 새로운 아이디어들이 결합되어 만들어진 하나의 작품이라고 보면 될 것 같습니다.
DALL-E 2는 이렇게나 복잡하고 정교하게 만들어져 있지만, 단점이 아예 없는 것은 아닙니다. 우선, 글자를 출력하는 능력이 떨어집니다.
이제 DALL-E 2가 어떻게 학습되었는지를 다시 정리해 보겠습니다. 우선, CLIP이라는 독립적인 인공지능을 가져와서 이미지와 문장을 N차원 좌표계로 대응합니다. 그 과정에서 그림과 문장의 유사도를 쉽게 알 수 있게 됩니다. 이후 DALL-E 2는 자신에게 입력된 문장을 문장 좌표로 바꾸고, 이를 Prior에 통과시켜 이미지 좌표를 만듭니다. 이 이미지 좌표는 최종적으로 이미지를 제작하는 디코더에 맨 처음 입력된 문장과 함께 입력되고, 우리가 원하는 이미지가 출력되는 것입니다. DALL-E 2는 여러 기존 인공지능 모델들과 새로운 아이디어들이 결합되어 만들어진 하나의 작품이라고 보면 될 것 같습니다.
DALL-E 2는 이렇게나 복잡하고 정교하게 만들어져 있지만, 단점이 아예 없는 것은 아닙니다. 우선, 글자를 출력하는 능력이 떨어집니다.

그림 10. DALL-E 2에 “Deep Learning이 써 있는 표지판”을 입력했을 때의 결과
그림 10을 보면, 입력값과 전혀 다른 글자들을 출력하는 것을 알 수 있습니다.

그림 11. DALL-E 2에 ‘타임 스퀘어’를 입력했을 때의 결과
또한, 디테일이 떨어집니다. 예를 들어 그림 11과 같이 DALL-E 2에 ‘타임 스퀘어’를 입력하면 타임 스퀘어의 휘황찬란한 전광판들의 형태는 잘 출력되지만 전광판의 내용은 전혀 출력되지 않습니다.
DALL-E 2가 새롭게 만든 질문들
최근에 DALL-E 2를 누구나 쓸 수 있게 되자 큰 파장이 일었습니다. 그림의 ‘창의성’이라는 것은 언제나 인간 고유의 것으로, 인간 외의 다른 객체들이 따라할 수 없다고 여겨졌기 때문입니다. 기존에도 만화를 그리거나, 그림을 그리거나, 소설을 쓰는 인공지능들이 많이 개발되었지만, 대부분은 “아직 아니다” 라고 평가받았습니다. 그러나 이번에 화제가 된 DALL-E 2의 경우, 실제 예술가들이 그린 그림과 구분하기가 굉장히 어렵습니다.
실제로, 지난 8월 26일 미국 콜로라도주에서 열린 미술대회에서는 제이슨 M. 알렌이 우승을 차지했는데, 사실 그 그림이 Midjourney라는 DALL-E 2와 비슷한 인공지능의 작품이라는 사실이 밝혀지면서 큰 논란이 되기도 했습니다.
최근에 DALL-E 2를 누구나 쓸 수 있게 되자 큰 파장이 일었습니다. 그림의 ‘창의성’이라는 것은 언제나 인간 고유의 것으로, 인간 외의 다른 객체들이 따라할 수 없다고 여겨졌기 때문입니다. 기존에도 만화를 그리거나, 그림을 그리거나, 소설을 쓰는 인공지능들이 많이 개발되었지만, 대부분은 “아직 아니다” 라고 평가받았습니다. 그러나 이번에 화제가 된 DALL-E 2의 경우, 실제 예술가들이 그린 그림과 구분하기가 굉장히 어렵습니다.
실제로, 지난 8월 26일 미국 콜로라도주에서 열린 미술대회에서는 제이슨 M. 알렌이 우승을 차지했는데, 사실 그 그림이 Midjourney라는 DALL-E 2와 비슷한 인공지능의 작품이라는 사실이 밝혀지면서 큰 논란이 되기도 했습니다.

그림 12. 제이슨 M. 알렌(Jason M. Allen)의 출품작 ‘Space Opera Theater’ (Midjourney로 제작)
그림 참 멋지지 않나요? 실제로 이 그림은 심사위원들에게 “르네상스 시기의 그림 같다” 라며 극찬을 받았습니다. 알렌은 작품을 출품하면서 분명히 Midjourney라는 툴을 활용해서 제작했다고 명시했지만, 심사위원들은 그것이 포토샵과 같은 이미지 편집 툴인 줄 알았다고 합니다. 그뿐만이 아니라, 알렌은 우승 이후 Midjourney가 사실은 인공지능이라는 사실을 밝히고도 아무런 제재도 받지 않았습니다. 대회 규정에 ‘인공지능을 사용하면 안 된다’와 같은 규정은 단 한 마디도 없었기 때문입니다.
많은 작가들이 이에 반발했습니다. 다른 작가들은 창의적이면서도 자신들이 잘 표현할 수 있는 아이디어를 얻기 위해 수많은 시간을 고뇌하고, 그보다 더한 시간을 들여서 힘들게 그려낸 작품을 대회에 출품하는데, 작품을 위해 전혀 노력하지 않은 알렌이 인공지능으로 30초만에 만든 그림을 출품해서 우승했다는 것입니다. 이들의 분노를 표출한 SNS 게시물이 9만 개 이상의 ‘좋아요’를 받기도 했습니다.
하지만 알렌은 즉각 반박했습니다. 알렌은 자신이 상상한 그림을 그대로 구현해내기 위해서 인공지능에 900번 이상 문장을 입력했다고 합니다. 인공지능이라고 항상 같은 그림을 내놓는 것도 아니고, 같은 뜻이더라도 다른 단어를 사용했을 때의 결과가 많이 달라질 수 있기 때문입니다. 결국 자신도 인공지능이 좋은 그림을 내놓게 하기 위한 문장을 구상하기 위해 다른 작가들만큼 고뇌하였다는 것이 알렌의 주장입니다.
실제로 알렌을 옹호하는 사람들도 많습니다. 마치 포토샵과 같이 인공지능도 작가를 보조하는 ‘도구’로 보아야 한다는 것입니다. 결국 인공지능에 입력을 넣는 것은 사람이기 때문에 여전히 그림의 중심 아이디어는 인간에 의해 결정된다는 뜻입니다. 결론적으로 인간의 창의성이 곧 예술의 본질이며 이를 부정할 필요는 없다는 것이죠.
인공지능이 가지는 도덕적인 문제들도 많습니다. DALL-E 2는 결국 인간이 찍고 그린 이미지들을 기반으로 만들어졌습니다. 즉, 인공지능이 그린 그림은 창의적이라고 말하기 어렵고, 결국 이미 누군가가 그린 그림을 표절한 것에 불과하다는 것입니다. 이 명제가 참인지 아닌지를 구분하는 것은 매우 어려운 철학적 문제입니다.
또한, 데이터의 편향에 의한 문제들도 많습니다. 인공지능의 데이터는 결국 인간이 만든 것이기 때문에 사회적인 고정관념이 인공지능의 결과물에 반영되기도 합니다. 대표적으로, DALL-E 2에 축구 경기를 하는 사람들의 이미지를 요청하면 대부분 남자의 모습을 나타냅니다. 또, DALL-E 2의 결과물은 대부분의 경우에서 서양의 색채가 강하게 반영되어 있습니다. 많은 양의 데이터를 사용하는 이상 현 시점에서 이러한 편향을 피하기는 기술적으로 어렵습니다. 인공지능이 대중들에게 창작의 주체로 확고히 인정받기 위해서는 이런 문제들이 개선되어야 할 것입니다.
여러분들은 어떻게 생각하시나요? 인공지능을 사용한 작품도 하나의 어엿한 예술로 인정받을 수 있을까요? 인공지능의 도덕적인 한계를 어떻게 극복할 수 있을까요? 오늘은 인공지능과 인류 미술의 미래가 어떤 모습일지 상상의 나래를 펼쳐보는 것도 좋겠네요! :D
많은 작가들이 이에 반발했습니다. 다른 작가들은 창의적이면서도 자신들이 잘 표현할 수 있는 아이디어를 얻기 위해 수많은 시간을 고뇌하고, 그보다 더한 시간을 들여서 힘들게 그려낸 작품을 대회에 출품하는데, 작품을 위해 전혀 노력하지 않은 알렌이 인공지능으로 30초만에 만든 그림을 출품해서 우승했다는 것입니다. 이들의 분노를 표출한 SNS 게시물이 9만 개 이상의 ‘좋아요’를 받기도 했습니다.
하지만 알렌은 즉각 반박했습니다. 알렌은 자신이 상상한 그림을 그대로 구현해내기 위해서 인공지능에 900번 이상 문장을 입력했다고 합니다. 인공지능이라고 항상 같은 그림을 내놓는 것도 아니고, 같은 뜻이더라도 다른 단어를 사용했을 때의 결과가 많이 달라질 수 있기 때문입니다. 결국 자신도 인공지능이 좋은 그림을 내놓게 하기 위한 문장을 구상하기 위해 다른 작가들만큼 고뇌하였다는 것이 알렌의 주장입니다.
실제로 알렌을 옹호하는 사람들도 많습니다. 마치 포토샵과 같이 인공지능도 작가를 보조하는 ‘도구’로 보아야 한다는 것입니다. 결국 인공지능에 입력을 넣는 것은 사람이기 때문에 여전히 그림의 중심 아이디어는 인간에 의해 결정된다는 뜻입니다. 결론적으로 인간의 창의성이 곧 예술의 본질이며 이를 부정할 필요는 없다는 것이죠.
인공지능이 가지는 도덕적인 문제들도 많습니다. DALL-E 2는 결국 인간이 찍고 그린 이미지들을 기반으로 만들어졌습니다. 즉, 인공지능이 그린 그림은 창의적이라고 말하기 어렵고, 결국 이미 누군가가 그린 그림을 표절한 것에 불과하다는 것입니다. 이 명제가 참인지 아닌지를 구분하는 것은 매우 어려운 철학적 문제입니다.
또한, 데이터의 편향에 의한 문제들도 많습니다. 인공지능의 데이터는 결국 인간이 만든 것이기 때문에 사회적인 고정관념이 인공지능의 결과물에 반영되기도 합니다. 대표적으로, DALL-E 2에 축구 경기를 하는 사람들의 이미지를 요청하면 대부분 남자의 모습을 나타냅니다. 또, DALL-E 2의 결과물은 대부분의 경우에서 서양의 색채가 강하게 반영되어 있습니다. 많은 양의 데이터를 사용하는 이상 현 시점에서 이러한 편향을 피하기는 기술적으로 어렵습니다. 인공지능이 대중들에게 창작의 주체로 확고히 인정받기 위해서는 이런 문제들이 개선되어야 할 것입니다.
여러분들은 어떻게 생각하시나요? 인공지능을 사용한 작품도 하나의 어엿한 예술로 인정받을 수 있을까요? 인공지능의 도덕적인 한계를 어떻게 극복할 수 있을까요? 오늘은 인공지능과 인류 미술의 미래가 어떤 모습일지 상상의 나래를 펼쳐보는 것도 좋겠네요! :D
- 그림출처
- 그림 1, 2: DALL-E 2 논문 원문, https://arxiv.org/abs/2204.06125
- 그림 3. https://openai.com/blog/dall-e/
- 그림 4. https://openai.com/dall-e-2/
- 그림 5. 직접 제작
- 그림 6. 직접 제작, 농구 이미지: El Gráfico 잡지 1993년 1월호 축구 이미지: JTBC 뉴스(2020-02-06)
- 그림 7. DALL-E 2 논문 원문, https://arxiv.org/abs/2204.06125
- 그림 8,9: 직접 제작
- 그림 10. DALL-E 2 논문 원문, https://arxiv.org/abs/2204.06125
- 그림 11. DALL-E 2 논문 원문, https://arxiv.org/abs/2204.06125
- 그림 12. https://www.nytimes.com/2022/09/16/learning/are-ai-generated-pictures-art.html